OrioleDB fastpath search

When you optimize the CPU time of a transactional database management system, it comes down to one question: how fast can you read a page without breaking consistency? In this post, we explore how OrioleDB avoids locks, trims memory copies, and — starting with beta12 — even bypasses both copying and tuple deforming altogether for fixed-length types during intra-page search. This means that not only are memory copies skipped, but the overhead of reconstructing tuples is also eliminated. The result: an even faster read path, with no manual tuning required.
Why page copies matter … and why they hurt
Every time a PostgreSQL backend descends an OrioleDB B-tree, it needs a consistent view of the target page. Instead of locking the whole page, OrioleDB keeps a 32-bit state word in the page header.
The low bits represent a change count that increments with every data modification; the high bits hold lightweight flags for "exclusive" and "read-blocked" states. A reader copies the necessary bytes, then re-reads the state, and retries if the counter has changed without using locks, yet achieving perfect consistency.
The following pseudo-code illustrates how to copy a consistent page image using a state variable for synchronization.
def read_page(page, image):
while true:
state = read_state(page)
if state_is_blocked(state):
continue
copy_data(image, page)
newState = read_state(page)
if state_is_blocked(state) or get_change_count(newState) != get_change_count(state):
continue
return
Copy only what you need
Obviously, copying the full 8KB page might be exhausting, especially when you only need it to locate a single downlink to navigate through the tree. That's why the OrioleDB page layout is chunked; the search code first grabs the small high-key strip (one high-key per chunk) to determine which chunk can possibly contain the key and then copies just that chunk.
The following pseudo-code illustrates how to copy only part of the page containing the given key.
def read_page_for_key(page, image, key):
while true:
state = read_state(page)
if state_is_blocked(state):
continue
copy_hikeys(image, page)
newState = read_state(page)
if state_is_blocked(state) or get_change_count(newState) != get_change_count(state):
continue
chunkIndex = locate_chunk(image)
copy_chunk(image, page, chunkIndex)
newState = read_state(page)
if state_is_blocked(state) or get_change_count(newState) != get_change_count(state):
continue
return
This is quite fair, and OrioleDB worked so till beta11.
Fast-Path search (new in OrioleDB beta12)
With beta12, OrioleDB goes a step further for simple, fixed-length data types (int4, int8, float4, float8, oid, tid):
- Skip the copy altogether: read the values directly from the in-memory page and check the state variable later. It's essential that comparison operations over inconsistent data for these datatypes can't lead to an error.
- Implement an array scan with a fixed stride for intra-page search instead of tuple deformation. When the search begins, the engine traverses the array with a fixed stride, utilizing only the type-specific comparison logic within the tight loop. Latency is reduced by predictable memory loads instead of pointer chasing.
The following pseudo-code illustrates the "fast path" approach for locating the downlink associated with the given key.
def fastpath_read_page_for_downlink(page, image, key):
while true:
state = read_state(page)
if state_is_blocked(state):
continue
chunkIndex = fastpath_locate_chunk(page, image, key)
newState = read_state(page)
if state_is_blocked(state) or get_change_count(newState) != get_change_count(state):
continue
itemIndex = fastpath_locate_key(page, image, key, chunkIndex)
downlink = fastpath_get_downlink(page, image, key, chunkIndex, itemIndex)
newState = read_state(page)
if state_is_blocked(state) or get_change_count(newState) != get_change_count(state):
continue
return downlink
This optimization should provide substantial benefits when there are many random in-memory lookups, such as heavy nested loops. The chart below shows the results for the pgbench script, which fetches 50 random values from pgbench_accounts on a 24xlarge instance. The performance boost is more than 20%!
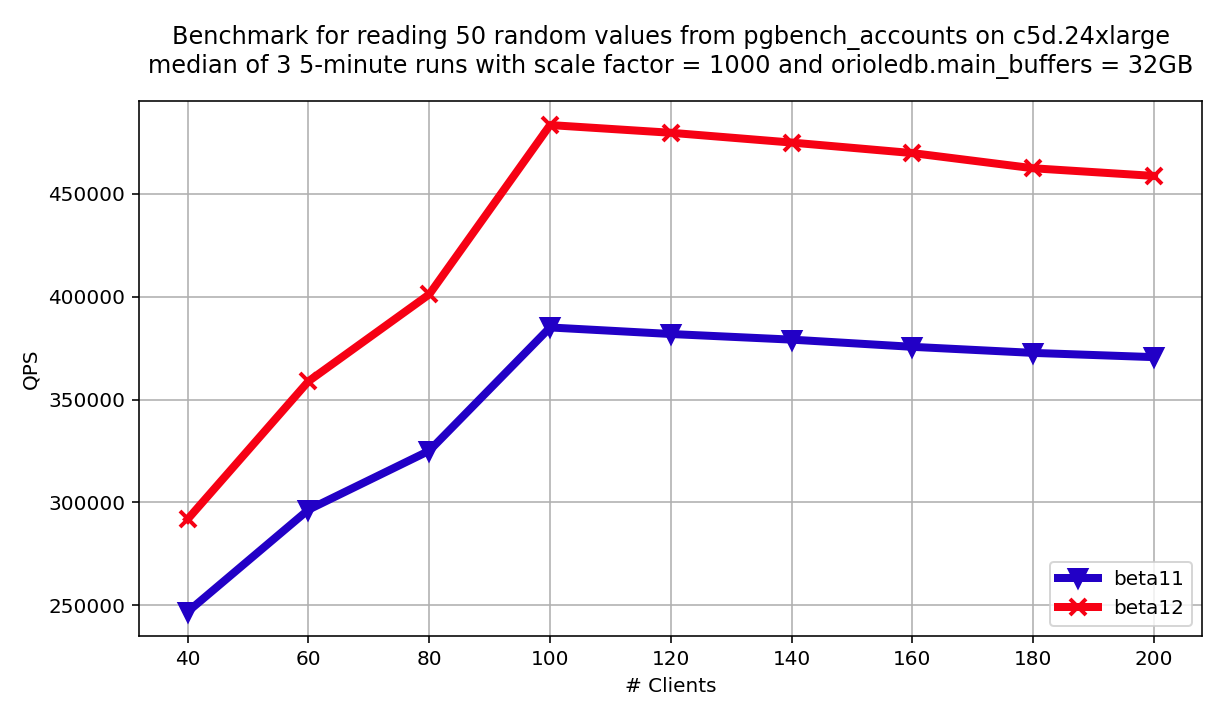
Conclusion
Fast-Path intra-page search shows how much performance you can unlock by shaving unnecessary memory copy out of the read path — and you don't even have to flip a switch. From beta 12 onward, OrioleDB automatically enables fast-path search whenever the index key consists of supported fixed-length types.
Suppose your workload is heavy on point reads, such as primary key or secondary key lookups. In that case, upgrading is effectively a no-brainer: you get lock-free consistency, cache-friendly chunking, and zero-copy scans that can push throughput by 20% — all without a single line of tuning in postgresql.conf.
The bottom line: with OrioleDB, "fast" is now the default path.