OrioleDB beta15 and beta16: stability, testing, and replication hardening

The beta15 and beta16 cycles together cover roughly four months of work on OrioleDB. Where previous releases introduced headline features such as non-B-tree index support, tablespaces, and undo-based rewind, these two releases are deliberately focused on stability, correctness, and test coverage. The goal is simple: make every existing feature work reliably under real-world conditions, especially replication, recovery, and concurrent workloads.
What is OrioleDB?
OrioleDB is a PostgreSQL storage extension that implements a custom Table Access Method as a drop-in replacement for the default heap storage engine. It is designed to address scalability bottlenecks in PostgreSQL's buffer manager and WAL subsystem, enabling better utilization of modern multi-core CPUs and high-performance storage.
By rethinking core components such as MVCC, page caching, and checkpoints, OrioleDB improves throughput in transactional workloads without altering PostgreSQL's user-facing behavior.
Why a stability-focused stretch?
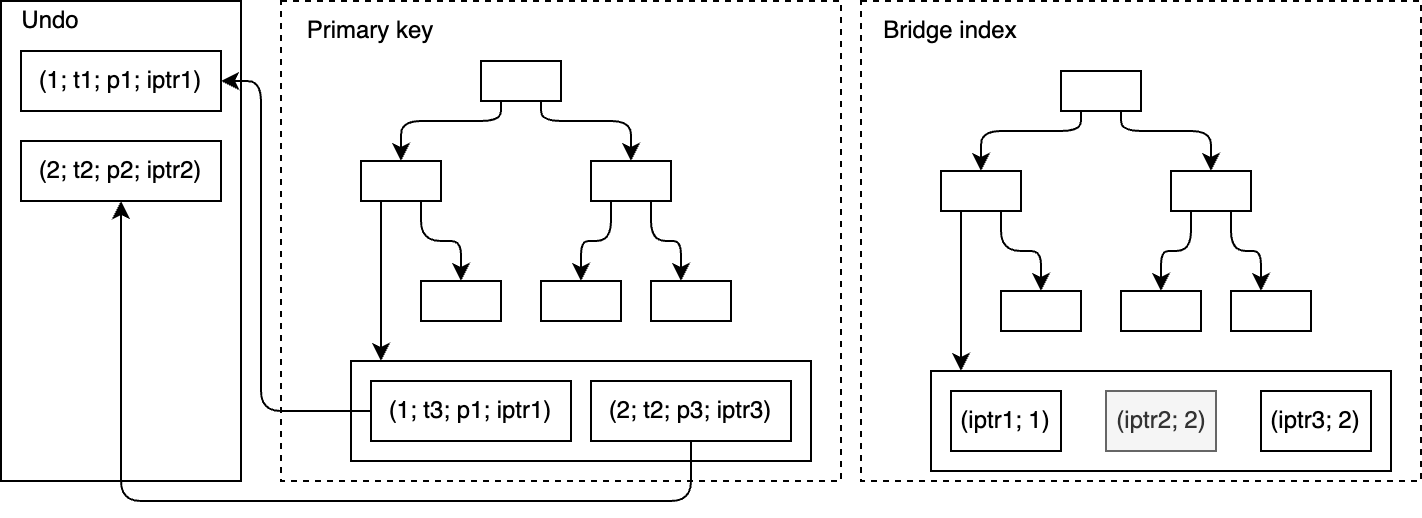
After several feature-heavy cycles, the OrioleDB team shifted focus to hardening the engine against edge cases exposed by broader adoption and more aggressive testing. The combined beta15+beta16 work contains numerous bug fixes spanning recovery, physical and logical replication, checkpointing, undo management, bridge indexes, page pool, and B-tree internals, plus separate fixes for various races during concurrent operations. Rather than adding new surface area, these releases make the existing surface area solid.