Why PostgreSQL needs a better API for alternative table engines?

For a long time now, PostgreSQL has had an extensible Index Access Method API (called AM), which has stood the test of time and enabled numerous robust extensions to provide their own index types. For example: rum, pgvector, bloom, zombodb and others. PostgreSQL 12 introduced the Table AM API, promising equivalent flexibility for table access methods.
Despite PostgreSQL's Table AM API being available since version 12 and ongoing criticisms of its built-in storage engine — particularly the MVCC model ([1], [2], [3]) — it remains surprising that no fully featured transactional storage engine has yet emerged purely as an extension.
Since the table AM and index AM APIs are tightly coupled, this is an issue for both implementations.
The features most in demand for alternative PostgreSQL table engines are:
- Alternative MVCC implementations, e.g.., UNDO-log-based storages. The motivation to provide this is well-discussed in Uber blog post, Andy Pavlo blog post, and many other sources.
- Non-heap-like storages. For example, in index-organized tables, the index is not an optional addition to the table that speeds up requests but a necessary layer the table storage uses internally. Consequently, the table tuple is a part of a complex data structure and can’t be addressed by a fixed-length address like page number and offset number. It requires to be addressed by variable length identifier like index key.
The API extension to provide #2 is more or less understandable. This could be done by replacing ctid with an arbitrary sequence of bytes in all the APIs. However, #1 seems rather complex and requires much clarification.
As an example that illustrates the motivation for the changes to the table and index AM API comes OrioleDB. It is an extension providing a table access method we developed to address many well-known shortcomings of the built-in storage engine. However, OrioleDB is not yet a drop-in extension; it requires several patches to the PostgreSQL Core.
Besides these two things, which will be discussed below, there are numerous needs for further API improvements, like pointer squizzling and alternative WAL-logging, that are outside the scope of this post.
Challenges for alternative MVCC-implementation
The table AM API doesn't directly force the way MVCC is implemented. Nevertheless, index AM and table AM APIs make the following assumption: every TID is either indexed by all the indexes or not indexed at all. Even if index AM has multiple references to the single TID (like GIN), all these references should correspond to the same indexed value.
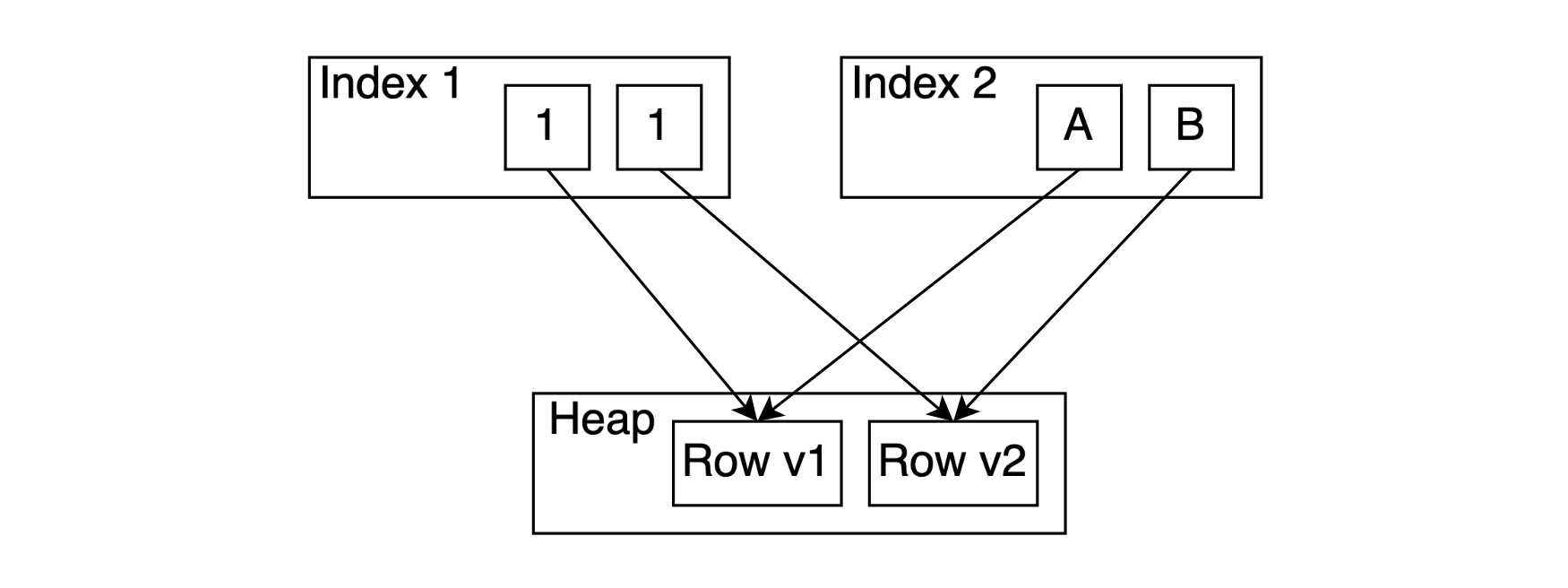
This principle was criticized for its write amplification. If you update one indexed attribute, you have to insert it into every index. Also, if we want to fully use the advantages of undo log or build other write-amplification-free storage method (e.g. WARM technique), we must break this assumption.
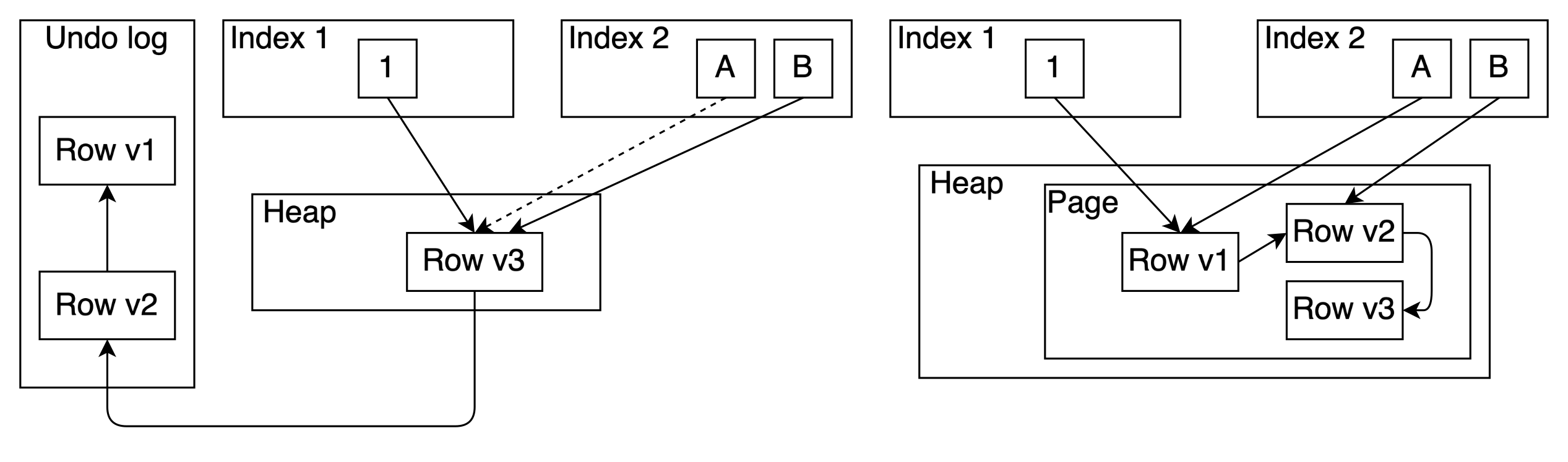
The undo access method that doesn’t break this assumption would be very similar to the existing HOT technique, except that old row versions are stored in the undo log and don't have to fit the same page. And in my point, this is not what justifies a table AM.
Let's see how this assumption is practically enforced at the API level.
- During an update of a table row, indexes are updated in an all-or-nothing manner. The signature of the table AM update method is below: an implementation can only set the value of
update_indexes.
/* see table_tuple_update() for reference about parameters */
TM_Result (*tuple_update) (Relation rel,
ItemPointer otid,
TupleTableSlot *slot,
CommandId cid,
Snapshot snapshot,
Snapshot crosscheck,
bool wait,
TM_FailureData *tmfd,
LockTupleMode *lockmode,
TU_UpdateIndexes *update_indexes);
The corresponding enum is exactly all-or-nothing except if have a special value to handle BRIN. And even if we add another special value to this enum, currently there is still no place to store index update policies on per-index basis
/*
* Result codes for table_update(..., update_indexes*..).
* Used to determine which indexes to update.
*/
typedef enum TU_UpdateIndexes
{
/* No indexed columns were updated (incl. TID addressing of tuple) */
TU_None,
/* A non-summarizing indexed column was updated, or the TID has changed */
TU_All,
/* Only summarized columns were updated, TID is unchanged */
TU_Summarizing,
} TU_UpdateIndexes;
- Lack of "point delete" method in index AM API to delete particular tuples. Currently, we can delete tuples from indexes in a bulk manner using the
ambulkdeleteandamvacuumcleanupmethods. Whether to delete a particular TID is determined by calling a callback (see a picture below). This leads to low efficiency as most current implementations have to scan the whole index. Also from the several tuples that could be referenced by one TID the method can not choose which one it should delete. It can delete only all of them.
/* Typedef for callback function to determine if a tuple is bulk-deletable */
typedef bool (*IndexBulkDeleteCallback) (ItemPointer itemptr, void *state);
/* bulk delete */
typedef IndexBulkDeleteResult *(*ambulkdelete_function) (IndexVacuumInfo *info,
IndexBulkDeleteResult *stats,
IndexBulkDeleteCallback callback,
void *callback_state);
/* post-VACUUM cleanup */
typedef IndexBulkDeleteResult *(*amvacuumcleanup_function) (IndexVacuumInfo *info,
IndexBulkDeleteResult *stats);
- As mentioned before, indexes currently reference table rows by block number and offset number. And only 11 bits of offset number could be safely transferred from table TID to all index access methods. However, alternative MVCC implementations could need to store additional payload together with TID. We need one or a few bits to implement "delete-marking" indexes or even full visibility information.
Let's see how we can overcome this limitation. Generally, I see two ways to do this.
Approach 1: Index AM provides facilities for alternative MVCC implementation
While table AM remains responsible for all the MVCC stuff, index AM provides necessary facilities for alternative MVCC implementations, including storage of custom payload altogether with TIDs, the "point delete" method, and even the "point update" method (if a TID in the index can't be changed, the custom payload definitely can).
As we should allow multiple index tuples to reference the same TID, we must provide more information while fetching the appropriate tuple from table AM. That is, we might need to pass indexed values to index_fetch_tuple to recheck them with the table row version.
bool (*index_fetch_tuple) (struct IndexFetchTableData *scan,
ItemPointer tid,
Snapshot snapshot,
TupleTableSlot *slot,
bool *call_again, bool *all_dead);
With undo-based storage, where many row versions can reside in the same TID, a bitmap scan can probably work "as is". It could get way more false positives, though. But if we want to allow something like WARM, it would be good to provide a way for the table AM to redefine the bitmap scan. It's already possible with set_rel_pathlist_hook, but the retail way to do this would be better.
Approach 2: MVCC-aware indexes
The alternative would be to allow MVCC-aware indexes. That is, the executor (or arguably table AM) just calls index AM insert() and delete() methods, while index AM provides MVCC-aware scans. This would make index-only scans much simpler. Even whole table AM could be an interlayer storing the data in an index and providing index-organized tables.
One could say that MVCC information could significantly burden an index. However, we should remember that the index has much more freedom in compacting this information. That is, the heap has to keep space for the worst case when all the tuples on the page need to be marked as updated/deleted. In contrast, the index could have optimized storage for the average case while doing a page split in the worst case
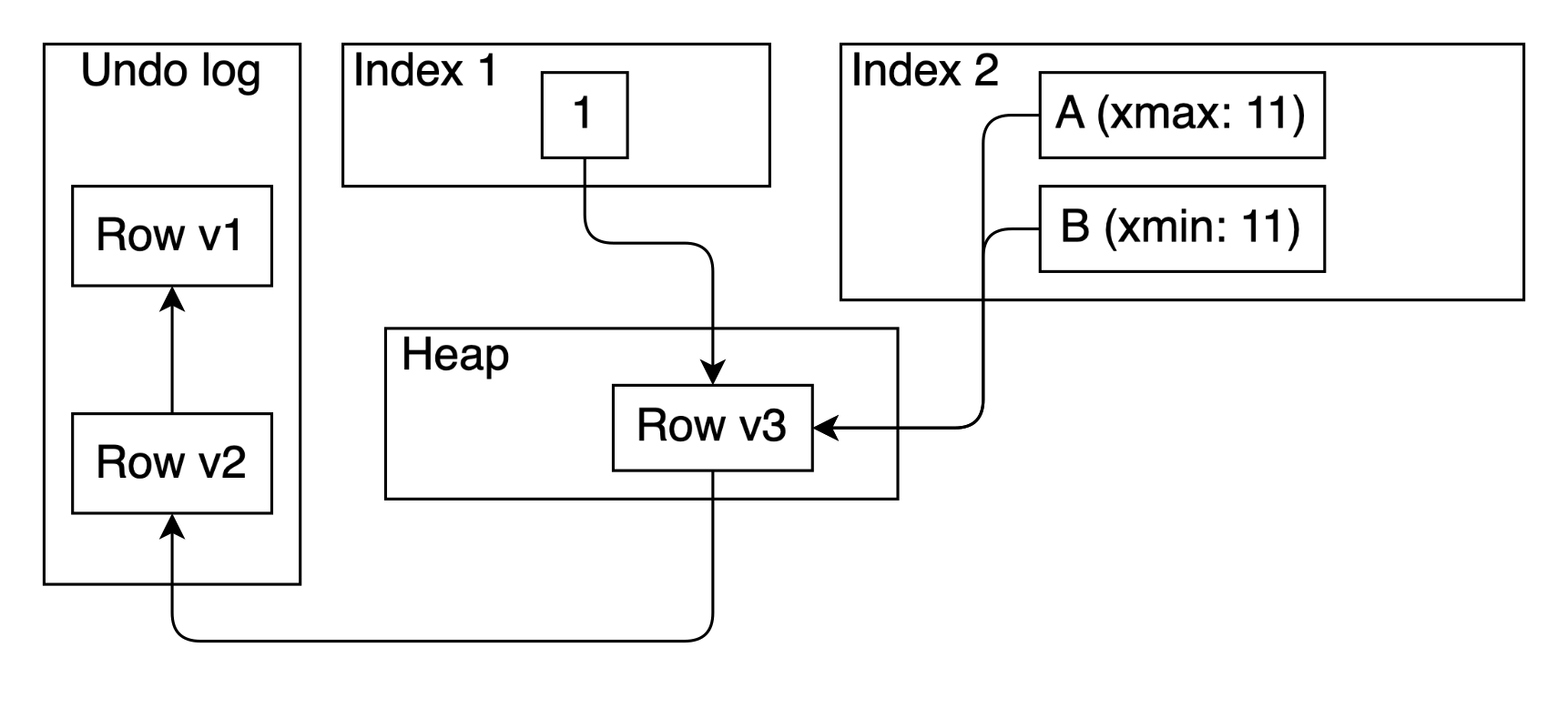
The example is given on the diagram below. The value of index 2 gets updated by transaction 11 from value A to value B. Therefore, value A is marked with xmax == 11 and value B is marked with xmin == 11. These values allows to scan index 2 and get only visible matches according to snapshot without checking the heap. Garbage collection of index 2 can be also performed without checking the heap. Also, note that we don’t need to reserve space for xmin of value A and xmax of value B, because we can perform a page split when needed.
Splitting index AM
The discussion above underscores that advancing PostgreSQL's index AM API for new storage models requires more than incremental changes. Given that existing index AMs are deeply intertwined with operator families, classes, and planner heuristics, and implementations assume a physical tuple identifier (TID) model, it is not feasible to enhance them with the capabilities needed for alternative MVCC implementations or index-organized tables. With a goal to leave all existing indexes and tables functionality unchanged, a more sustainable approach is to split index AM into two distinct layers:
- Logical Index AM. This layer would serve as the abstraction boundary interfacing with existing entities such as operator families and operator classes, exposing the information necessary for the query planner and inheriting existing planner hacks.
- Index AM Implementation. This layer does the hard work of the actual implementation of the index, including index page layout, insertion/deletion/search algorithms, etc. Particular implementations provide properties like MVCC awareness, support for arbitrary row identifiers, etc.
The diagram below illustrates the proposed separation. The logical index AM interacts with PostgreSQL's core (operator families, planner, etc.), while the index AM implementation encapsulates the actual indexing logic and storage details.

For instance, with this design extension can define both a new index AM with MVCC-aware B-tree implementation (defined in pg_am_impl). Via pg_am it will reuse all existing operator classes/families, planner hacks etc. This MVCC-aware B-tree would be tailored to serve to the undo-based table AM defined in this extension.
Conclusion
While PostgreSQL’s existing table and index AM APIs have served the community well over the years, the demand for alternative storage engines and MVCC implementations exposes inherent limitations in their current design. The challenges discussed—from the all-or-nothing update mechanism to the rigidity of TID-based indexing—underscore the need for a more flexible and nuanced approach. We can begin by supporting fully MVCC-aware indexes or extending index AM to support alternative MVCC strategies. Moreover, the proposed separation of index AM into logical and implementation layers is a promising direction that not only addresses current limitations but also lays the foundation for future innovations. This reimagined architecture could enable PostgreSQL to support diverse storage models, reduce write amplification, and improve overall system performance, ultimately opening the door to a more modular, scalable, and robust database ecosystem.