Ordered Insertion Optimization in OrioleDB

When many sessions try to insert into the same B-tree leaf page, classic exclusive page locking serializes progress and wastes time on sleep/wake cycles. We’re introducing a batch page insertion path that lets the session holding the page lock insert for itself and its neighbors. The result: dramatically reduced lock waits, and big gains at high client counts (2X throughput boost starting from 64 clients in our benchmark).
The problem: hot leaves and lock convoys
In OrioleDB beta12, inserts into a B-tree leaf are performed under an exclusive page lock. If several backends target the same leaf page, they queue, sleep, and wake up in turn.

That’s correct and simple — but not cheap:
- Every process waiting for the lock pays the cost of sleep → wake → re-check just to insert a tiny tuple.
- If the leaf is hot (e.g., time-ordered keys, skew, or tight key ranges), we get a huge queue on that single page.
- The lock hand-off cadence, not raw CPU, becomes the bottleneck.
The idea: cooperate while you hold the page
We introduced a cooperative scheme that transfers the insertion work to the process that already holds the leaf’s exclusive lock. Think of it as “group commit” for page inserts.

How the new batch page insertion works
-
Lockless list of waiting processes per page.
The lock-protected queue of page-lock waiting processes is replaced with a lockless list (we will call it a “wait list”), so publishing intent is wait-free for followers.
-
The waiting process publishes the tuple.
Before a process queues for the page lock, it publishes its tuple (key + payload + a small control meta-information) into shared memory and links it into the page’s wait list.
-
The lock holder process batch insert.
When a process inserts into the leaf page (under the lock), it also scans the wait list, collects the already-published tuples whose keys belong to that page, and inserts as many as fit, along with its own tuple.
-
Waking up is usually a no-op.
When the original inserters wake, many find their tuple is already inserted. They will just proceed.
If the batch filled the page and forced a split, the remaining inserters re-check the page’s hikey and may follow the rightlink, similarly to a standard insert after a split.
This is pure cooperation: no session is required to help others, but the lock holder has the best vantage point to make progress at a low cost for the group.
Thanks to this scheme, the lock holder performs N inserts for at least one lock handover. The N is limited by the wait list size and the number of tuples that can be inserted into the page with split. So, under high concurrency, the lock holder can grow one page at a time. This is great compared to inserting one tuple at a time.
Benchmark
The benchmark was performed on an AWS EC2 c7gd.metal machine with 64 Graviton3 vCPU. The simple benchmark is simulating an IoT (Internet of Things) workload. The DDL for this benchmark is given below.
CREATE TABLE measure (
sensor_id int NOT NULL,
ts timestamp NOT NULL,
value float8 NOT NULL,
PRIMARY KEY (sensor_id, ts)) USING orioledb;
CREATE INDEX measure_ts_idx ON measure(ts);
The measure table stores measures coming from sensors at paricular moments of time. The measure_ts_idx index on timestamp provides an effective way to query slices of measures. Obviously, this index will have ordered inserts and will suffer from lock convoys on its rightmost leaf page. The pgbench script simulates the insertion of measures for 10 sensors in one query.
INSERT INTO measure VALUES
(:client_id * 10, current_timestamp, random()),
(:client_id * 10 + 1, current_timestamp, random()),
(:client_id * 10 + 2, current_timestamp, random()),
(:client_id * 10 + 3, current_timestamp, random()),
(:client_id * 10 + 4, current_timestamp, random()),
(:client_id * 10 + 5, current_timestamp, random()),
(:client_id * 10 + 6, current_timestamp, random()),
(:client_id * 10 + 7, current_timestamp, random()),
(:client_id * 10 + 8, current_timestamp, random()),
(:client_id * 10 + 9, current_timestamp, random());
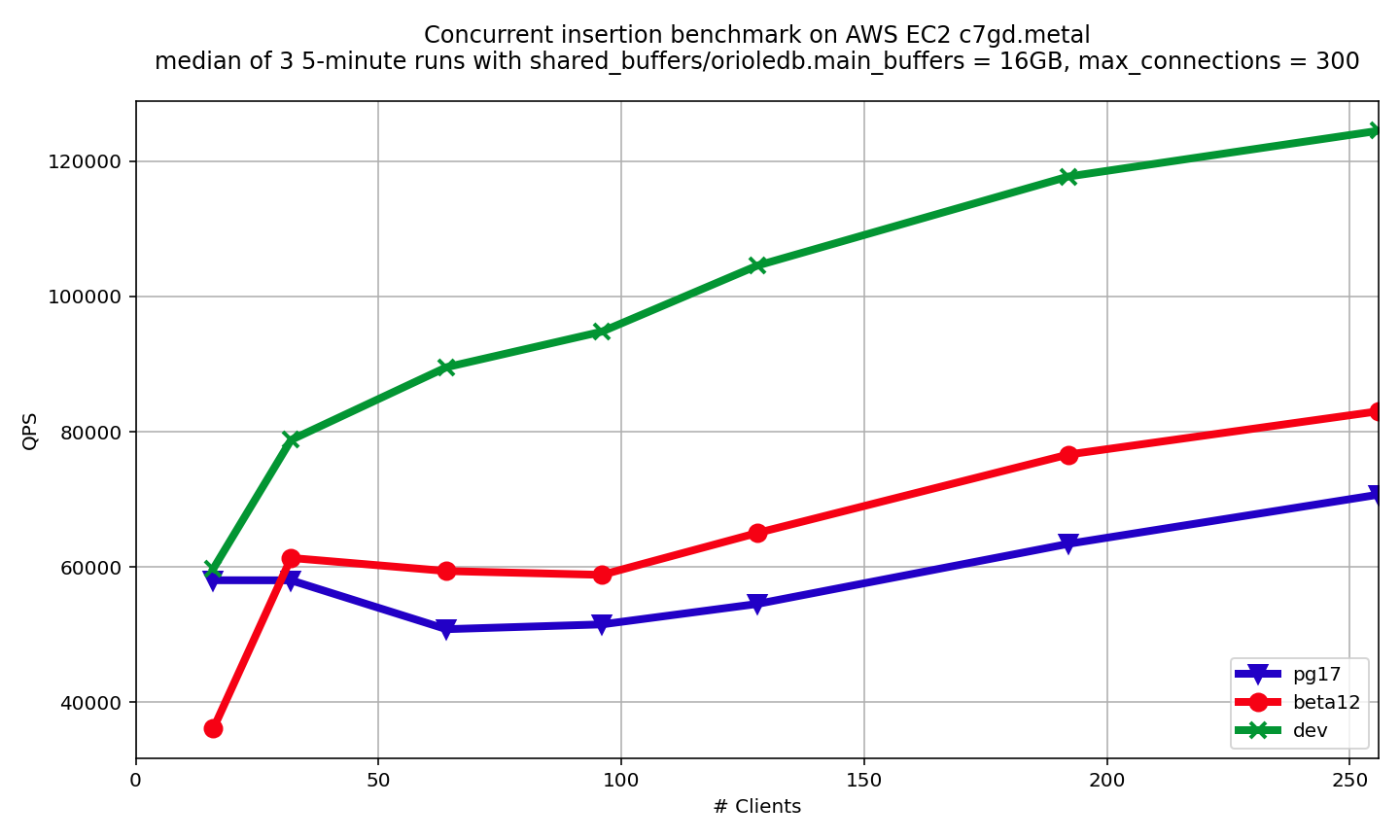
-
OrioleDB beta12 vs. PostgreSQL heap
OrioleDB beta12 appears to be slower than PostgreSQL heap on 16 concurrent connections, but shows 10%-20% speedup starting from 64 connections.
-
Batch page insertion
Batch page insertion optimization dramatically improves the situation by reducing lock waits. While having no regression, it shows almost 2X speedup starting from 64 connections.
Try it and tell us what you see
If your workload shows skewed keys or time-based ordering (IoT, event logs, time-series dimensions, append-heavy OLTP), you’re a prime beneficiary. The optimization is now on our main branch and will be published in the OrioleDB beta13 release. We’d love to hear your results and traces — especially at 64+ clients where the gains are most significant.